개발자-기획자 모두를 위한 다국어 관리 시스템 개선하기
들어가며
이전 회사 위블링의 오라운드 서비스에서 다국어 관리 시스템을 개선했던 경험을 공유하고자 합니다.
오라운드는 기획 초기부터 한국뿐만 아니라 일본, 영어권 등 다양한 글로벌 사용자를 염두에 둔 서비스였습니다. 제가 합류했을 때, 프로젝트는 외주사로부터 막 인계받은 상태였고 i18next를 사용해 다국어가 적용되어 있었습니다.
기존 다국어 관리 방식의 비효율
당시 프로젝트는 신규 기능 개발이 최우선이었기에, 다국어 지원은 기본적인 적용 수준에 머물러 있었습니다. 특히 일본 서비스 론칭도 계획하고 있었기 때문에 번역문을 지속적으로 수정해야 하는 상황이었습니다.
문제는 번역 리소스가 단일 JSON 파일로 관리되고 있었으며, 대부분의 키(key)가 번역문 원본(한글)이었고 번역 값 또한 불일치하는 경우가 많았습니다.
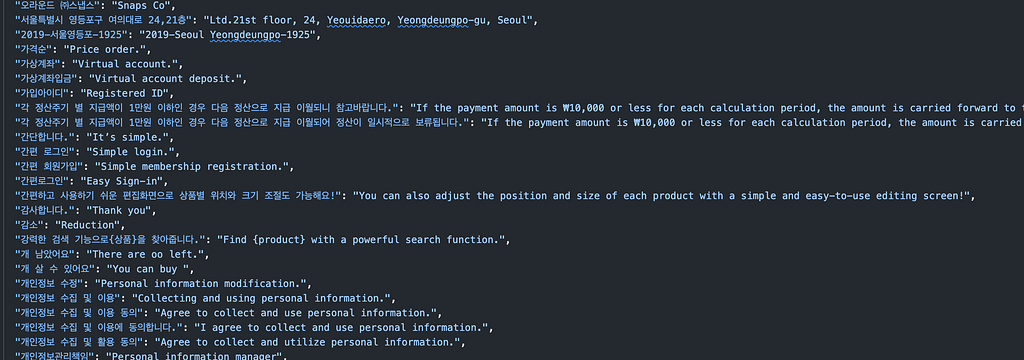
이러한 관리 방식은 네 가지의 비효율을 가져왔습니다.
-
커뮤니케이션의 비효율 — 번역 리소스가 프로젝트 내 JSON 파일로만 관리되어 개발자와 기획자 간 번역 상태 공유가 실시간으로 되지 않아 많은 커뮤니케이션이 필요했습니다.
-
잦은 휴먼 에러 — 값을 불러오는 과정에서 JSON 리소스의 키 값 매칭이 되지 않거나, JSON 파일 수동 입력 과정에서 오타나 키 누락 등의 실수가 빈번했습니다.
const { t } = useTranslation(LOCALIZE_GROUPS);
<button type="button" className="btn_primary type3 full" onClick={(e) => handleLink('/')}>
<span>{t('아트워크 감상하러 가기')}</span>
</button>
-
데이터 정합성 문제 — 여러 사람이 수동으로 관리하다 보니 데이터의 일관성이 깨지기 쉬웠습니다.
-
성능 저하 — 단일 파일로 관리되어 서비스 각 페이지에서 모든 리소스가 로드되어 초기 로딩량이 불필요하게 컸습니다.
이러한 문제점들을 개선하기 위해 구글 시트 동기화 작업을 결정했습니다.
자동화로 비효율적인 번역 작업 끝내기
자동화가 필요한 이유?
이번 작업은 NHN Cloud Meetup의 i18n 자동화 가이드를 참고하면서 방향을 잡았습니다.
구글 시트 자동화 프로세스는:
- 스캔 - 스크립트가 프로젝트 전체의 번역 키를 자동으로 추출합니다.
- 업로드 - 추출된 키를 구글 시트에 자동으로 업로드합니다.
- 다운로드 - 구글 시트에서 번역이 완료되면, 그 내용을 다시 프로젝트의 JSON 파일로 내려받습니다.
이 자동화가 앞서 언급한 문제들을 해결할 수 있다고 판단했습니다.
이 작업을 통해 기획자가 직접 번역 상태를 관리하며 커뮤니케이션 비효율과 데이터 정합성 문제를 해결하고, 개발자는 스크립트 기반으로 작업하여 휴먼 에러를 줄일 수 있었습니다. 또한 작업 과정에서 파일을 분리하며 성능 저하 문제도 함께 개선할 수 있었습니다.
기반 다지기: 컨벤션 정의 및 파일 분리
자동화 작업을 위해 정해진 프로세스에 맞게 실행되고 관리되려면 컨벤션이 필요했습니다.
첫째, 구글 시트를 번역 데이터의 단일 진실 공급원(Single Source of Truth)으로 삼았습니다. 모든 번역의 기준을 구글 시트로 옮기면서 단순 공유를 넘어, 기획자에게 번역 관리의 주도권을 넘겨드리고자 했습니다. 그리고 데이터의 신뢰도를 높였습니다.
둘째, 데이터를 정제하고 분류하기 위해 네임스페이스, 키값 등의 규칙을 정했습니다. 네임스페이스(ns)를 기준으로 UI 용도에 맞게 파일 디렉토리를 나누고, key||property 규칙으로 JSON 내 데이터 계층을 구조화하여 구글 시트와 일관성 있게 동기화하도록 했습니다.
<span>{i18next.t("$CS_INQUIRE_MODAL||ESSENTIAL", { ns: "common/modal" })}</span>
// locales/en/common/modal.json
"$CS_INQUIRE_MODAL": {
"ESSENTIAL": "You should fill out this item."
}
자동화 구현: 스캔, 업로드, 다운로드 스크립트
정해진 규칙에 따라 스캔 → 업로드 → 다운로드 프로세스의 스크립트로 구성했습니다.
// package.json
{
"scripts": {
"scan:i18n": "i18next-scanner --config i18next-scanner.config.js",
"upload:i18n": "node translate/upload.js",
"download:i18n": "node translate/download.js"
}
}
스캔(scan:i18n)
i18next-scanner 라이브러리를 통해 미리 정의된 설정 파일을 바탕으로, 프로젝트 내에서 i18next.t 메서드가 사용된 코드를 모두 찾아 번역 키를 추출하고 JSON 파일에 자동으로 반영합니다.
// i18next-scanner.config.js
const path = require('path');
const COMMON_EXTENSIONS = '/**/*.{js,jsx,ts,tsx,vue,html}';
const { ns, loadPath, savePath, SEPARATE_KEY, NOT_MATCH } = require('./translate/constant');
module.exports = {
input: [`src/pages${COMMON_EXTENSIONS}`, `src/components${COMMON_EXTENSIONS}`],
options: {
defaultLng: 'ko',
lngs: ['ko', 'en', 'jp'],
func: {
list: ['i18next.t'],
extensions: ['.js', '.jsx', '.ts', '.tsx'],
},
ns,
resource: {
loadPath: path.join(__dirname, `${loadPath}/{{lng}}/{{ns}}.json`),
savePath: path.join(__dirname, `${savePath}/{{lng}}/{{ns}}.json`),
},
defaultValue(lng, ns, key) {
const keyAsDefaultValue = ['ko'];
if (keyAsDefaultValue.includes(lng)) {
return NOT_MATCH;
}
},
keySeparator: SEPARATE_KEY,
nsSeparator: false
},
};
input에 있는 디렉토리 파일에서 func.list의 i18next.t 메서드를 찾아 번역 키를 추출하고, resource의 경로를 따라 locales 디렉토리의 네임스페이스 별로 JSON 파일에 값을 자동으로 추가하게 됩니다.
예를 들어 언어값이 필요한 부분에 아래처럼 코드를 추가한 뒤 npm run scan:i18n 명령어로 스캔을 실행합니다.
// Modal/KoreaPost.tsx
<span>{i18next.t('$KOREA_POST||SEARCH_POST', { ns: 'common/modal' })}</span>
locales/common/modal.json 디렉토리 위치에 아래처럼 값이 자동으로 추가됩니다.
// locales/ko/common/modal.json
"$KOREA_POST": {
"SEARCH_POST": "N/M"
}
// locales/en/common/modal.json
"$KOREA_POST": {}
// locales/jp/common/modal.json
"$KOREA_POST": {}
여기서 한글 값은 직접 입력을 하고 나머지 외국 번역이 필요한 값은 업로드 프로세스를 통해서 자동으로 구글 시트에 추가되게 됩니다. 이렇게 되면 JSON에 수동으로 입력하지 않아도 되기 때문에 오타나 미입력 하는 실수를 방지할 수 있습니다.
업로드(upload:i18n)
업로드 스크립트는 먼저 로컬의 모든 번역 JSON 파일을 읽어 { [네임스페이스]: { [번역키]: { ko: '..', en: '..', jp: '..' } } } 형태의 통합된 객체(keyMap)로 재구성합니다. 그 후, 이 객체의 데이터를 구글 시트의 각 행에 맞게 평탄화(flatten)하여 시트에 업데이트합니다.
// upload.js
async function updateSheetFromJson() {
try {
const doc = await loadSpreadsheet();
// -- 구글시트 문서 객체를 불러옵니다.
fs.readdir(loadLocalesPath, (error, lngs) => {
// -- locales 폴더에 있는 모든 하위 폴더를 읽습니다.
if (error) {
throw error;
}
const keyMap = {};
// -- 번역 JSON 리소스를 저장할 객체입니다.
lngs.forEach((lng) => {
nameSpaces.forEach((ns) => {
const localeJsonFilePath = `${loadLocalesPath}/${lng}/${ns}.json`;
const json = fs.readFileSync(localeJsonFilePath, 'utf8');
gatherKeyMap(keyMap, lng, ns, JSON.parse(json));
// -- doc에 업로드하기 위해 하나의 통합된 객체로 만드는 로직입니다.
});
});
updateTranslationsFromKeyMapToSheet(doc, keyMap);
// -- 통합한 keyMap 객체를 doc 구글시트에 업로드합니다.
console.info('✨Finished upload');
});
} catch (err) {
console.log('upload updateSheetFromJson', err.message);
}
}
updateSheetFromJson();
다운로드(download:i18n)
구글 시트를 Single Source of Truth로 삼아, 시트의 최신 번역 내용을 로컬 JSON 파일에 덮어쓰는 방식으로 변경사항을 반영하여, 항상 최신 번역이 서비스에 반영되며 데이터의 정합성을 보장합니다.
// download.js
async function updateJsonFromSheet() {
try {
const doc = await loadSpreadsheet();
const lngsFileMap = await fetchTranslationsFromSheetToJson(doc);
// -- 구글시트의 행 데이터를 모두 가져오고 JSON파일의 데이터를 비교해 병합한뒤 데이터를 재조합합니다.
const lngs = fs.readdirSync(saveLocalesPath, 'utf8');
lngs.forEach((lng) => {
// -- locales 폴더의 모든 언어와 네임스페이스를 순회하고 JSON 파일을 처리할 준비를 합니다.
nameSpaces.forEach((ns) => {
const localeJsonFilePath = `${saveLocalesPath}/${lng}/${ns}.json`;
const jsonString = JSON.stringify(lngsFileMap[lng][ns], null, 2);
// git을 위해 한 줄 개행 함
const updatedJsonString = jsonString + '\n';
// -- 변환된 JSON 문자열을 실제 로컬 파일에 덮어쓰면서 파일을 업데이트 합니다.
fs.writeFileSync(localeJsonFilePath, updatedJsonString, 'utf8');
console.info(`Success download ${lng}/${ns}`);
});
});
console.info('✨Finished download');
} catch (err) {
console.log('updateJsonFromSheet error', err);
}
}
updateJsonFromSheet();
작업 결과: 협업 개선과 높아진 서비스 품질
협업 프로세스 개선
이번 개선 작업을 하면서 제일 크게 기대한 부분은 협업 프로세스 개선이었습니다.
모든 팀 구성원이 구글 시트를 단일 공급원으로 삼고 현황을 공유했기 때문에 이를 바탕으로 소모적인 커뮤니케이션이 사라졌습니다.

[Before]
기획자: "혹시 00부분에 번역이 되어 있을까요?"
개발자: "아 아직 번역이 안되어 있네요."(코드와 JSON 파일을 확인)
기획자: "그럼 00으로 번역 상태 추가 부탁드려요"
개발자: "네 번역 값 추가하고 다시 말씀드릴게요"(수정 후 다시 공유)
[After]
기획자: (구글 시트에 직접 번역 현황을 확인하고 수정을 완료한 후에) "00부분 번역 수정했는데 반영 부탁드릴게요~"
개발자: (메시지 확인 후에
npm run download:i18n실행) "네 확인했고 반영했어요"
기획자는 번역 상태를 묻거나 요청할 필요 없이 직접 내용을 확인하고 관리할 수 있게 되었습니다.
번역 누락 확인 요청, 단순 번역 요청, 동일한 컨텍스트에 대한 일괄 수정 등의 작업을 단 한 번의 요청으로 충분하게 됐습니다. 물론 UI 변경이 예상되는 부분은 추가적인 확인 소통이 필요했지만 대부분의 간단한 작업은 쉽게 해결됐습니다.
수치로 보면, 기존에는 번역 요청에 대한 리드타임이 길게 3~5시간이 걸리던 것이 짧으면 30분, 간단한 수정은 수 분 내로 해결되었습니다. 많게는 10번 이상 오가던 불필요한 대화가 사라지면서 개발팀은 잦은 맥락 전환 없이 핵심 개발 업무에 집중할 수 있는 환경을 얻게 되었습니다.
개발 환경의 개선: 안정성과 속도
휴먼 에러 방지로 개발 안정성 확보
번역 키 오타, 누락 등 직접 수작업으로 관리할 때 발생하던 휴먼 에러가 원천적으로 차단되었습니다.
이는 배포 전 QA 과정의 부담을 줄이고, 번역 관련 버그 발생률을 0%에 가깝게 만들어 서비스의 안정성을 크게 높였습니다.
네임스페이스 분리로 로딩 속도 개선
비효율적인 리소스 로딩 문제도 개선되었습니다.
기존에 하나의 파일에 약 71,127자에 달하던 리소스가 UI 단위의 네임스페이스로 분리하면서, 각 페이지에서 실제로 로드하는 리소스의 양이 평균 15,000자 내외로 75% 이상 감소하며, 사용자 경험 개선에 기여할 수 있었습니다.
마무리
기존에 수작업으로 관리된 다국어 시스템은 투입되는 노력에 비해 비효율이 큰 작업이었습니다. 처음에는 기능 구현만으로 이 문제를 해결할 수 있을 것이라 예상했습니다.
그러나 실제 개선 과정에서는 기능 개발은 물론, 팀 전체의 개발 컨벤션 정립까지 고려해야 하는 복합적인 작업이었고 예상보다 많은 노력이 필요한 과정이었습니다.
하지만 그 과정을 통해 비효율적인 커뮤니케이션을 줄여 팀 협업의 질을 높이고 서비스의 기술적 완성도를 개선하는 성과를 거둘 수 있었습니다.